The Alphyn.AI Team here. In this post we dig into a question that comes up frequently when planning enterprise data platforms: how much does dynamic data masking actually affect SQL query performance? We compare different masking approaches, look at how the query optimizer and execution engine behave with masked fields, and measure whether throughput degrades under concurrent load — specifically when using Apache Ranger as the policy enforcement layer.

The article answers four practical questions:
Does dynamic masking produce a noticeable increase in query execution time?
How do Ranger and the SQL engine behave under concurrent load when masking is active?
What happens when a masked field is used in filtering, aggregation, or a JOIN?
Which masking type is best suited to analytical workloads?
Background
Any enterprise-grade data platform must meet modern information security requirements, including restricting access to sensitive data for certain roles and user groups. Depending on the specific requirements and the system's security classification, the tools for doing this are either encryption or masking. This article focuses on masking.
One of the most common questions we hear from platform users and customers is: "We'd like to enable the built-in masking feature, but we don't understand how much performance degradation to budget for when planning compute capacity." This is a real design concern for analytical platforms: can you turn on dynamic data masking without taking a meaningful performance hit?
On paper it looks simple enough: in the platform's SQL engines, dynamic masking policies are enforced through the Apache Ranger role-based access plugin. When a query runs, the user receives a transformed version of the sensitive field value rather than the original. The transformation can be:
full redaction of the value;
showing only the last 4 characters, or only the first 4;
hashing;
NULL substitution.
From a security standpoint this is convenient — but how viable is it under production conditions? Especially when you're dealing not with isolated queries but with concurrent load, analytical queries, JOIN operations, and filtering over large tables.
We decided to measure how our Apache Ranger implementation actually behaves in practice.
The goal was straightforward: understand how different dynamic masking types affect SQL query execution time, system stability under load, and the correctness of analytical queries.
Why Test This at All
It matters where in the execution pipeline the masking transformation is applied. If the value is substituted at the very end — when the result is nearly ready to be returned to the user — that's one thing. But if the transformation is applied earlier, during data processing, it affects not just what the user sees but how the query is executed at all.
This is especially relevant for analytical workloads. Hiding a field is straightforward for simple data browsing, but what if the masked field is involved in a WHERE clause, a JOIN, or a GROUP BY? Users need to know in advance: will masking just hide the value in the output, or will it start meaningfully affecting query results?
Let's move on to the experiments.
Methodology and Results
To avoid conflating different effects, we split the testing into several distinct scenarios. The goal was to identify exactly where masking has negligible impact and where it becomes significant.
As always, we ruled out single-node testing. Every test configuration must approximate at least a minimal production deployment.
Our test cluster consisted of:
4 compute nodes deployed on Kubernetes;
24 vCores CPU per node;
220 GB RAM per node;
object storage backed by MinIO.
The baseline was a no-masking run, against which all other approaches were compared. Each masking type was tested against the same dataset — identical in volume and composition (except for the masked fields): a customers table (75 million rows) and an accounts table (150 million rows).
We worked from simple to complex.
1. Baseline scenario — plain SELECT
We started with the simplest case: a plain SELECT where masked fields are returned in the result set and filtering is done on a non-masked field. This test established a baseline to see how masking alone affects a query when nothing else is added.
For plain queries there was no meaningful degradation. The no-masking baseline averaged 1,801 ms. Full redaction came in at 1,935 ms (+7.4%). Hashing gave 1,870 ms (+3.8%). Showing the last 4 characters was actually slightly faster than the baseline at 1,709 ms, and NULL substitution showed the most pronounced reduction at 1,111 ms (−38.3%).
Masking type | Avg. returned data size, bytes | Avg. execution time, ms | Deviation from baseline, % |
No masking | 2307 | 1801 | 0.0% |
Full redaction | 2307 | 1935 | +7.4% |
Last 4 characters | 2299 | 1709 | −5.1% |
Hashing | 3518 | 1870 | +3.8% |
NULL substitution | 1118 | 1111 | −38.3% |
The "returned data size" column represents the total byte size of each row returned by the query. This largely determines how quickly the full result set is returned to the client and how much engine memory is consumed. We can see a direct correlation between how much data the engine needs to read and surface to the client, and execution time. Different masking modes affect the volume of returned data differently — and that translates into different resource consumption and execution time.
The overall picture: in a plain SELECT where masked fields appear only in the output and play no role in the query's computational logic, there is no significant degradation. In other words, the mere fact of masking does not cause queries to suddenly run much slower.
Test query
SELECT
contractor_id_int,
contractor_id_char,
last_name,
first_name,
middle_name,
birth_date,
contractor_type_id_int,
contractor_type_id_char
FROM
contractor
WHERE
birth_date BETWEEN '@start_period_date' AND '@end_period_date';2. Concurrent load
The next step was a more realistic scenario: multiple queries running in parallel. In a real system, users don't work one at a time, so it was important to find out whether masking introduces instability or unexpected response-time spikes under simultaneous load. It's worth noting that degradation can also depend on which SQL engine is used as the executor — Alphyn Lakehouse supports StarRocks, Impala, and Trino, each with different tolerance for concurrent load. This experiment was conducted on Impala.
All threads used the same query with fixed parameters. The query structure was kept constant so that any differences in results would be attributable to masking alone — not to variation in the data being scanned. We made this choice intentionally to isolate Ranger's behavior rather than the engine's. We publish regular benchmarks comparing MPP engines under concurrent load separately.
Each test ran 50 parallel threads, each executing 50 queries. Total queries per test iteration: 2,500. Average execution time was recorded.
Masking type | Avg. execution time, ms | Deviation from baseline, % |
No masking | 1999 | 0.0% |
Full redaction | 1999 | 0.0% |
Last 4 characters | 1089 | −45.5% |
Hashing | 1995 | −0.2% |
NULL substitution | 1398 | −30.1% |
The system behaved predictably. The no-masking baseline averaged 1,999 ms; full redaction also came in at 1,999 ms; hashing at 1,995 ms — essentially no difference. Last-4-characters and NULL substitution were faster than the baseline at 1,089 ms and 1,398 ms respectively (consistent with the findings on returned data volume from the previous test).
Looking specifically at concurrent load, nothing unexpected happened. The system ran smoothly, without surprises and without meaningful degradation attributable to masking itself. The key takeaway: Apache Ranger handled policy lookups from the SQL engine with ease — the real workload sits with the execution engine, not with Ranger.
3. Isolating the masking overhead itself
We then isolated the cost of the masking mechanism itself. The goal was to eliminate side effects and see how much execution time changes in a scenario where masking doesn't interact with more complex query logic.
Initially it seemed that value transformation would noticeably slow down queries. But in a simple scenario, it doesn't. As long as a masked field isn't involved in WHERE, JOIN, or aggregation, the overhead of the masking mechanism itself is small.
Masking type | Avg. execution time, ms | Deviation from baseline, % |
No masking | 229 | 0.0% |
Full redaction | 223 | −2.6% |
Last 4 characters | 212 | −7.4% |
Hashing | 234 | +2.2% |
NULL substitution | 186 | −18.8% |
Hashing added just +2.2% over the no-masking baseline: 234 ms vs. 229 ms. Full redaction came in at 223 ms, last-4-characters at 212 ms, NULL substitution at 186 ms.
4. Mixed load
We then tested a scenario where masked and unmasked queries run simultaneously. This matters in production: both access modes almost always coexist in a live system.
For full redaction, last-4-characters, and hashing, the difference versus the no-masking baseline was minimal — ranging from −0.9% to +0.3%. NULL substitution again showed a speedup relative to its paired no-masking run.
In short, the coexistence of different access modes was not itself a source of problems. The system can handle queries from both masked and unmasked users simultaneously without meaningful degradation from the mixing.
Masking type | Avg. returned data size, bytes | Avg. execution time, ms | Deviation from baseline, % | |
1 | No masking | 2307 | 1859 | 0.0% |
Full redaction | 2307 | 1857 | −0.1% | |
2 | No masking | 2288 | 1790 | 0.0% |
Last 4 characters | 2288 | 1774 | −0.9% | |
3 | No masking | 2307 | 1972 | 0.0% |
Hashing | 3518 | 1977 | +0.3% | |
4 | No masking | 2294 | 1427 | 0.0% |
NULL substitution | 1118 | 1122 | −21.4% | |
Each pair of rows compares the no-masking baseline with the corresponding masking mode under mixed load conditions.
5. Analytical scenarios
The most striking differences appeared in analytical scenarios. When a masked field is simply returned in a SELECT, things look relatively calm. The moment that field participates in query logic, the picture changes.
5.1. Filtering on a masked field
We first tested a scenario where the masked field appears in a WHERE clause. This is one of the most revealing cases, because the key question is: is the comparison performed against the original value or the transformed one?
The no-masking baseline ran in 643 ms. Full redaction came in at 5,527 ms (+759.6%), last-4-characters at 5,344 ms (+731.1%). Hashing gave 823 ms (+28.0%), and NULL substitution came in at just 43 ms (−93.3%).
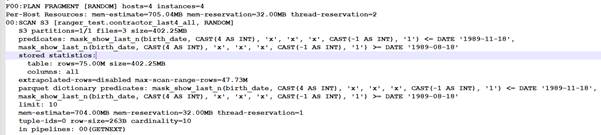
This is where it becomes clear that masking is no longer just "hiding a column from the user." The moment a field appears in a WHERE clause and is simultaneously masked, the system is no longer working with the original value — it's working with the transformed version.
This is most pronounced for full redaction and last-4-characters modes: for non-string types, an additional per-row transformation is effectively applied, which is why the query becomes dramatically slower.
Masking type | Avg. returned data size, bytes | Avg. execution time, ms | Deviation from baseline, % |
No masking | 2304 | 643 | 0.0% |
Full redaction | 128 | 5527 | +759.6% |
Last 4 characters | 128 | 5344 | +731.1% |
Hashing | 128 | 823 | +28.0% |
NULL substitution | 128 | 43 | −93.3% |
5.2. Aggregation over masked data
In the second analytical scenario, the JOIN was performed on a non-masked field while aggregation ran on data with NULL substitution applied. Here we were interested not only in execution time but in how the result's meaning changes.
Execution time was lower than the no-masking baseline: 2,969 ms vs. 4,210 ms (−29.5%), due to the reduced result set volume.
But speed is less important here than correctness. The aggregation was being performed not on original values, but on transformed ones. The query ran without errors and returned results — but interpreting those results requires care: they reflect the masked representation of the data, not the underlying values.
This is the case where the query doesn't break, but it starts computing something fundamentally different from what it would compute without masking.
Masking type | Avg. returned data size, bytes | Avg. execution time, ms | Deviation from baseline, % |
No masking | 450 | 4210 | 0.0% |
NULL substitution | 212 | 2969 | −29.5% |
5.3. JOIN on a NULL-substituted field
We then tested a JOIN on a masked field in NULL substitution mode. The result is predictable — but no less important for that.
When a join key is substituted with NULL, no matches are found, the JOIN produces no paired rows, and the join effectively collapses. Execution time in this scenario was 3,076 ms vs. 5,832 ms for the baseline (−47.3%).
But this is a case where faster does not mean better. The query runs faster because genuine row matching is no longer happening. From an analytical standpoint, this mode is completely unusable for join keys.
Masking type | Avg. returned data size, bytes | Avg. execution time, ms | Deviation from baseline, % |
No masking | 451 | 5832 | 0.0% |
NULL substitution | 52 | 3076 | −47.3% |
5.4. JOIN on a hash-masked field
Finally, the most interesting scenario: a JOIN on a field masked via hashing.
The logic is intuitive — identical source values produce identical hashes, so in theory data can be joined without exposing the originals. And indeed, in this scenario the JOIN worked correctly: rows were returned, aggregation and grouping ran without issues. But the latency was severe: 113,083 ms vs. 8,857 ms for the no-masking baseline — a +1,176.8% increase.
Masking type | Avg. execution time, ms | Deviation from baseline, % |
No masking | 8857 | 0.0% |
Hashing | 113083 | +1176.8% |
This is arguably the most important finding in the entire study. Hash masking does preserve analytical join-ability, but in complex scenarios it comes with a severe performance cost.
Let's look at the query execution profile to understand why. First, a comparison of the aggregated operation statistics.


The aggregated plan shows a significant increase in scan time. Let's check the detailed text plan.


In the HASH JOIN node, the optimizer is aware of the pk/fk relationship between the join keys across tables — but the actual join is executed on mask_hash(pk/fk). When building the JOIN fragment, the engine creates a bloom filter. Without masking, this bloom filter is successfully applied by the scan fragment, which reads only 16.2 million rows from the full dataset thanks to min/max filtering on the Parquet storage index. With masking active, the scan node can no longer use that bloom filter and must read the full 150 million rows — which is the primary cause of the dramatic slowdown.
Conclusions
First — dynamic masking on its own is not a problem for ordinary queries. If a masked field is simply returned in the result set and plays no role in the query's computational logic, the performance impact is usually small. This holds for plain reads, concurrent workloads, and mixed access modes alike. Apache Ranger handles intensive policy-lookup traffic from the SQL engine with ease, because the real computational burden sits with the execution engine.
Second — the real complexity begins not when a field is hidden from the user, but when that field is touched by WHERE, GROUP BY, or JOIN. That's where masking stops being purely cosmetic and starts affecting the query execution logic itself.
Third — different masking types suit different use cases. NULL substitution hides data effectively but completely disables analytics on those fields when they're used in joins or calculations — it's best described as "blocking access to final output data," such as a pre-computed data mart. Partial masking that shows only 4 characters is convenient for display, but can dramatically slow down certain filtering scenarios. In practice, first-4 or last-4 masking can be usable even for some analytical tasks. Hashing is the most interesting trade-off: it preserves value comparability and determinism across JOINs and GROUP BY operations, but can impose significant performance penalties in complex analytical queries.
And perhaps the central takeaway — dynamic masking in the Alphyn Lakehouse is a valuable built-in feature that lets you avoid the old-school approach of building separate view layers for every restricted role. That said, choosing a masking type must be treated as a query-design decision, not just a security policy choice.
We are currently running load tests in a production-scale environment with a total Ranger role count between 50,000 and 100,000. Stay tuned for the follow-up.
See it on your own data
If you're weighing how this would handle your workloads, we'd be glad to walk you through Alphyn Lakehouse on a real scenario. Book a sovereign-lakehouse walkthrough →
About Alphyn.AI
We build the Alphyn Lakehouse, a Kubernetes-native, high-performance, multi-engine lakehouse for any enterprise data and analytical workload — from agentic AI and BI to structured and unstructured data. Built entirely on open standards and an open architecture, Alphyn Lakehouse is a sovereign, on-premises solution for regulated enterprises across the GCC and the wider MENA region.